Filtering Bear.app's recent files in Alfred
One feature I like to have in any notes editor is a way to quickly get back to my most recently edited files. Obsidian has a community plugin for this, but I don’t love relying on community plugins. That’s part of why I moved to Bear.app.
In Bear, you can sort any list of notes by modification date, but it takes a couple clicks to accomplish. It’s also got forward/back shortcuts, which are useful for hopping around. And there’s the Today view, which is handy. But when I’m busy and trying to get back to that one note — what was it called? — with minimal cognitive flailing and without resorting to the mouse, I want something even easier. Or at least, something that my synapses are already wired for.
I just built that thing in Alfred, my preferred launcher. It was pretty easy and fun! Here’s how to do it, in case it’s helpful.
Note: If you’re considering this specific use case, definitely check out the real-deal Alfred plugin, drgrib/alfred-bear. It doesn’t work for me because it compiles its Go code to binaries, which get flagged and blocked on my work laptop. Otherwise I would have started there.
Creating the workflow
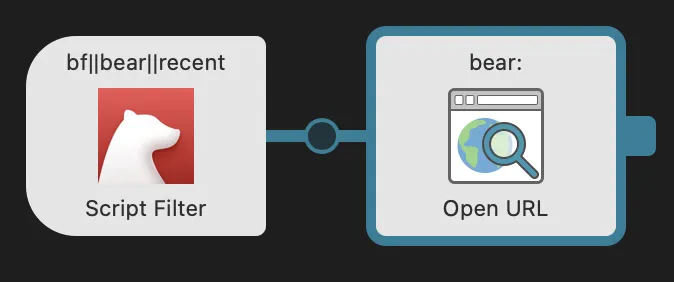
First, I created a new Alfred workflow and added a Script Filter Input. That input lets me provide Alfred with a list of arbitrary things to present and filter on.
Next, I figured out how to query Alfred’s SQLite database. Helpfully, Alfred documents how to find it. I copied the database file to a backup that I could use to safely experiment on. I love how easy that is with SQLite.
Next, I opened the backup database with DBeaver to make it easy to explore the schema. I saw a table that looked promising, poked around its columns, and came up with this simple query to pull the most recent notes’ titles and unique identifiers:
SELECT ZUNIQUEIDENTIFIER, ZTITLE
FROM ZSFNOTE
ORDER BY ZMODIFICATIONDATE DESC
LIMIT 20
I then wrapped that in a Python script to generate the JSON that Alfred wants for its script filter input (code modified for brevity):
import json
from pathlib import Path
import sqlite3
import sys
db_path = (
Path.home()
/ "Library/Group Containers/9K33E3U3T4.net.shinyfrog.bear/Application Data/database.sqlite"
)
if not db_path.exists():
raise ValueError(f"No db found at path: {db_path}")
# Open in read-only mode (https://stackoverflow.com/a/21794758)
con = sqlite3.connect(f"file:{db_path}?mode=ro", uri=True)
cur = con.cursor()
items = []
for row in cur.execute(QUERY):
uid, title = row
items.append({"title": title, "arg": uid})
filter_input = {"items": items}
sys.stdout.write(json.dumps(filter_input))
Then, back in the Alfred workflow UI, I hooked the script filter input up to an Open URL Action with the following URL template, which I generated with Bear’s super helpful URL builder:
bear://x-callback-url/open-note?id={query}&show_window=yes&open_note=yes
And that’s it!
Here’s what the workflow looks like in the UI:
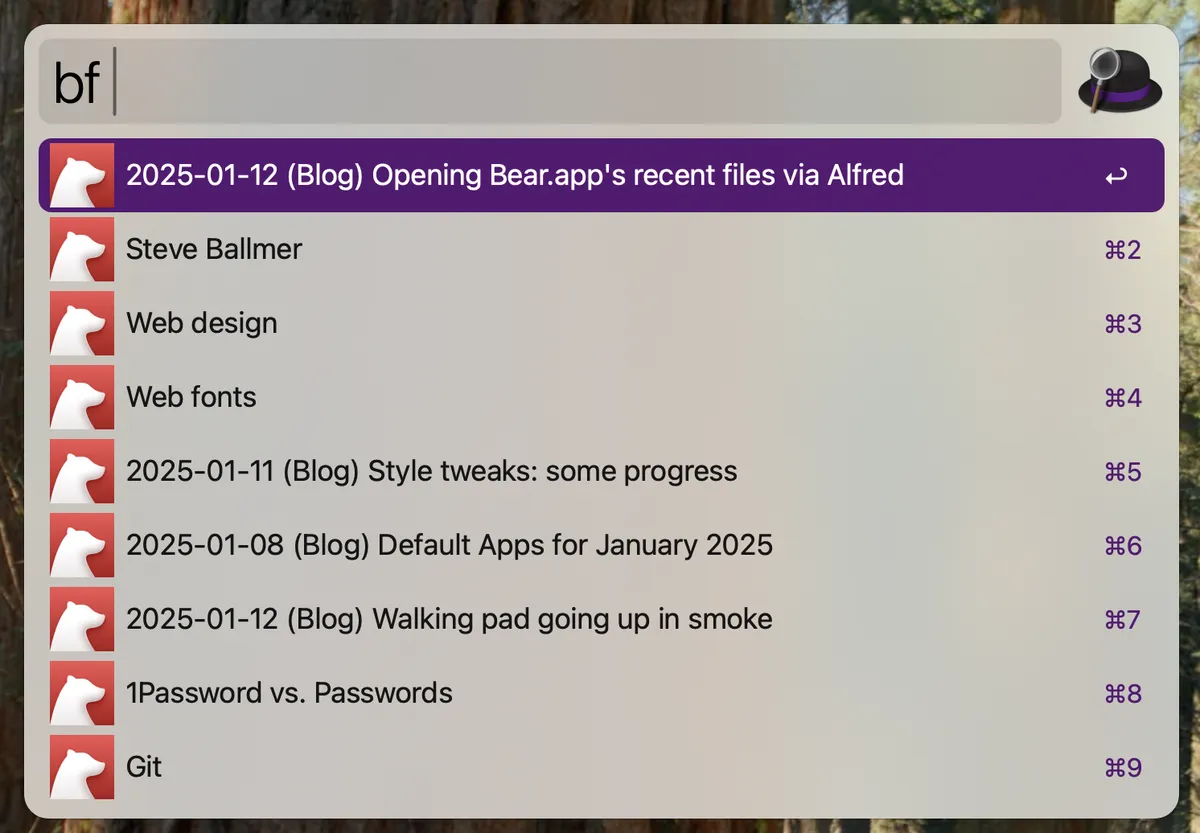
And here’s the result1:
Followup notes
The LIMIT
I’ve bumped up the LIMIT parameter to 500, and I’ll keep tweaking it.
Bear can filter tens of thousands of list items at the speed of thought.
I might get rid of the limit altogether.
To make tweaking that limit easier, I made it so I can optionally set the limit number in an environment variable. Bear makes it easy to access the environment config in the workflow UI. For those newer to Python, here’s a way to read a variable in a relatively safe way:
QUERY_LIMIT = int(os.getenv("BEAR_RECENT_QUERY_LIMIT", "100"))
- The
"100"parameter is a default. So if the environment variable isn’t set, the script (a) will have a useful number to work with, and (b) won’t explode. - Casting the value to
intis something of safeguard against malicious SQL injection (or just sloppy input). It will error out if the string isn’t just a number. For example:
>>> int("drop table")
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
ValueError: invalid literal for int() with base 10: 'drop table'
- On that note, if you’re also newer to SQL: before parameterizing a query, you should at least have a 101-level understanding of SQL injection. Codeacademy has a good guide. And, obligatory xkcd.
- Disclaimer: I haven’t been a software engineer for about 10 years now. Please consider this entire post to be advice from a novice, and seek the advice of actual experts where appropriate.
Script Input Filter config
If you want Alfred’s filtering to be super fast, take a look at the Alfred filters results checkbox in the input’s config. By default, Alfred will assume your script wants to handle the filtering, so it will re-run your script each time your filter input changes, passing your input as a parameter to the script. If your script does anything computationally expensive, this could be slow.
If you check that checkbox, Alfred will run your script just once, and then keep all the results in memory and handle the filtering. So far, that’s what I’ve wanted in all my workflows. Docs here.
Why Steve Ballmer, you might be wondering? 😉 I stumbled across Dan Luu’s post, Steve Ballmer was an underrated CEO, and wanted to capture it for posterity. I was poking around Dan’s site looking for discussion of his reluctance to use any
max-widthin his blog’s CSS. See this HN thread.↩